在 Trae IDE 中利用 MCP 高效抓取与收录网络文章
2026-01-19 · 技术解析
背景
在维护 奥升官网(基于 Nuxt 3 构建)的过程中,我们需要将发布在其他平台的技术文章迁移到官网的内容管理系统中。手动复制粘贴不仅效率低下,还容易遗漏图片资源或导致格式错乱。
借助 Trae IDE 及 Chrome MCP,我们可以将这一过程高度自动化。本文将详细介绍这套抓取方案的思路与实现。
环境与工具
本方案依赖以下核心环境与工具:
- Trae IDE: 新一代 AI 驱动的集成开发环境(我使用的国际版,开了会员),可调用 Gemini-3-Pro-Preview 模型,支持复杂的上下文理解与多步任务执行。
- MCP (Model Context Protocol):
- mcp_chrome: 提供浏览器自动化能力,用于访问网页、读取 DOM 结构、截图等。
抓取思路
整个抓取流程可以概括为以下四个步骤:
- 目标分析: AI 通过 MCP 浏览器工具访问目标 URL,解析页面结构,识别标题、正文、发布时间及图片链接。
- 内容提取: 将 HTML 内容转换为符合 Nuxt Content 规范的 Markdown 格式,并自动提取 Frontmatter(元数据)。
- 图片处理:
- 自动下载文章中的图片到
public/images/articles目录,并按文章id分文件夹存储。 - 使用
sharp对图片进行压缩优化(WebP/JPG 转换、尺寸调整)。 - 将图片按上传到 OSS 指定文件路径中。
- 替换 Markdown 中的图片链接为 OSS 上的路径。
- 自动下载文章中的图片到
- 自动收录: 将处理好的 Markdown 文件写入
content/articles/目录。
关键实现
1. 页面内容读取
利用 MCP 的 chrome_read_page 或 chrome_get_web_content 工具,我们可以直接获取渲染后的页面内容,这对于动态加载的页面尤为重要。
2. 图片资源的自动化处理
1. 提取链接
AI 会从 DOM 中找出所有 <img> 标签的 src 属性。
2. 批量下载
AI 会生成并执行 Shell 命令(如 curl 或 wget)来下载图片。
# AI 自动生成的下载命令示例
mkdir -p public/images/articles/21
curl -o public/images/articles/21/1.jpg http://example.com/path/to/image.jpg
3. 图片压缩
利用项目中的 sharp 脚本对下载的图片进行批量处理,确保加载性能。
4. 图片上传到 OSS
使用ali-oss 库,编写 upload_oss 脚本,将压缩后的图片上传到 OSS 上指定的目录。
async function uploadFile(filePath, retryCount = 0) {
// 处理上传到oss的文件路径
const relativePath = path.relative(articlesDir, filePath);
const objectName = `website/article/${relativePath.split(path.sep).join('/')}`;
try {
const result = await client.put(objectName, filePath);
//...
} catch (err) {
//...
}
}
3. Markdown 生成与 Frontmatter 注入
Nuxt Content 要求每篇文章包含特定的元数据。我们定义了统一的 Prompt 模板,让 AI 生成标准格式:
---
title: 文章标题
slug: article-slug
description: 文章摘要...
date: 2024-03-20
category: 分类
cover: https://ucode-orise.oss-cn-beijing.aliyuncs.com/website/article/[slug]/cover.jpg
---
## 正文内容
...
实际效果展示
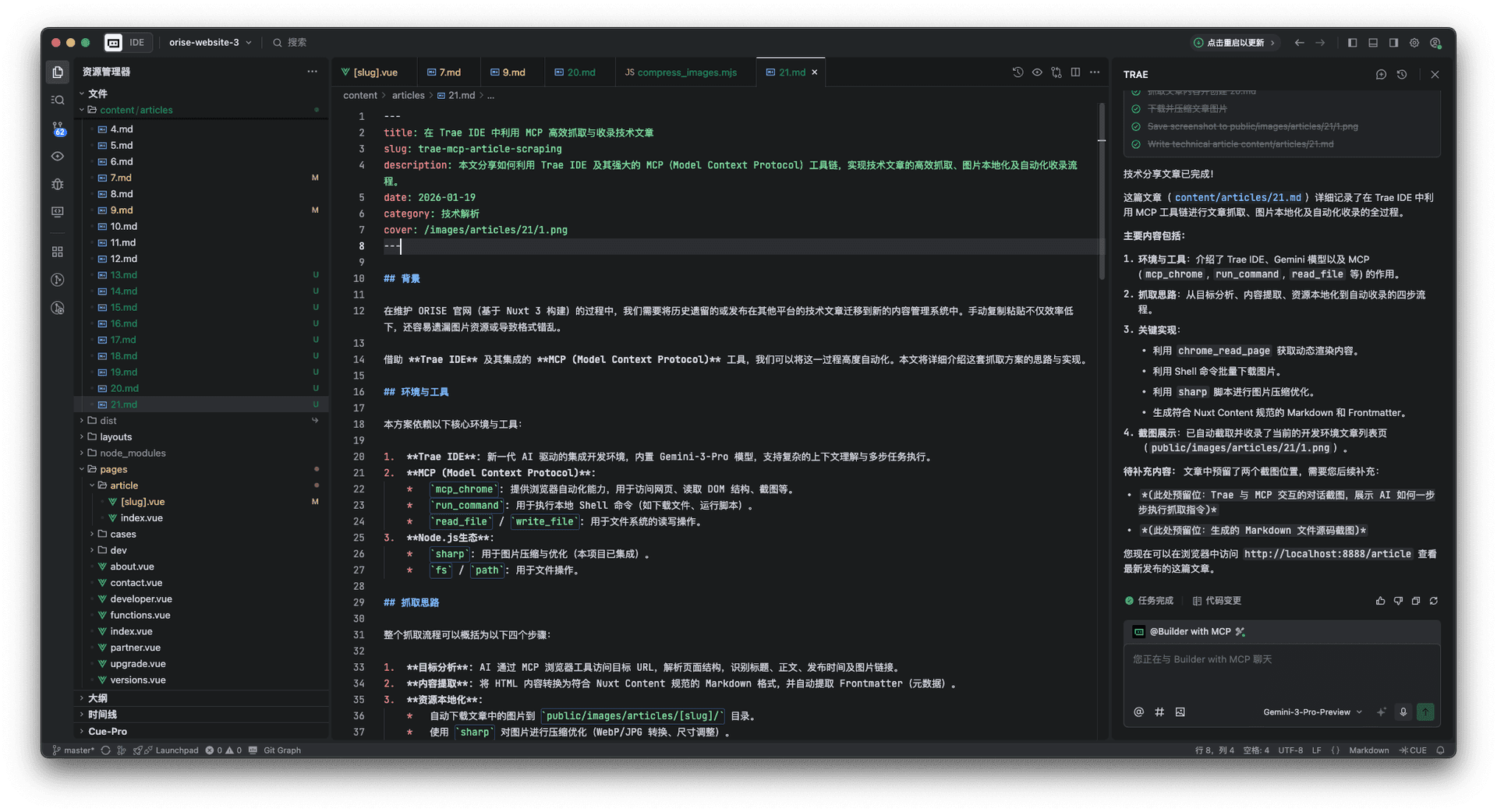
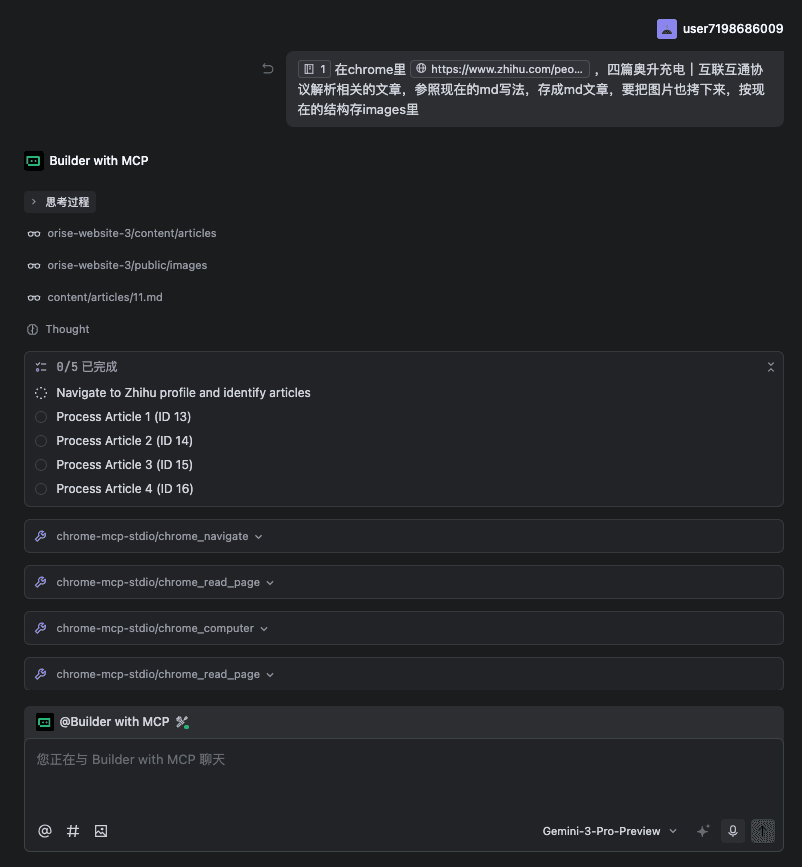
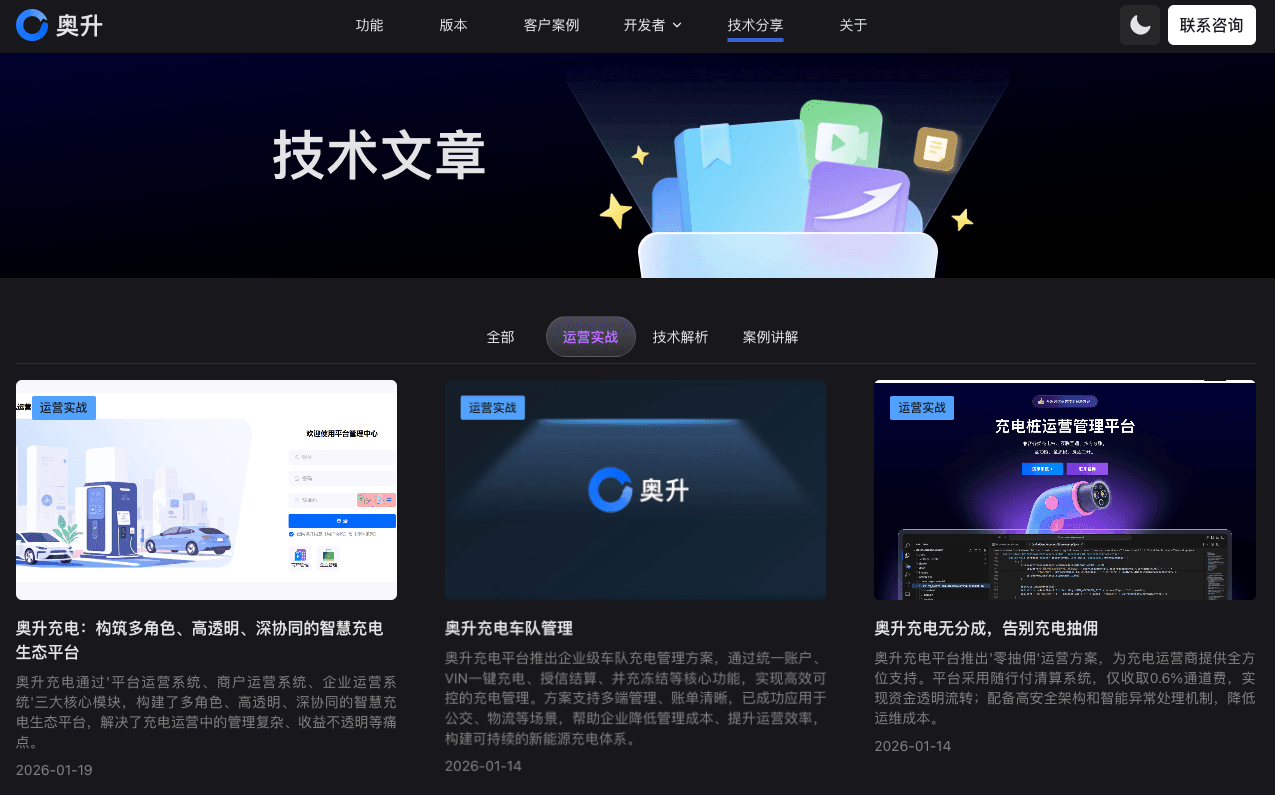
下图是我们在 Trae 环境中开发时的文章列表页面截图,展示了收录后的效果:
总结
通过 Trae IDE + MCP 的组合,我们将原本需要 10 分钟/篇的人工迁移工作缩短到了 2-3 分钟/篇(主要是AI对话推理时间)。开发者只需提供一个 URL,剩下的分析、下载、转换、优化工作全部由 AI 代理完成。这不仅极大提升了效率,还保证了代码风格与目录结构的一致性。